
We’ll learn something new in today’s article about understanding the architecture of an Azure Databricks Spark Cluster and Spark Jobs.
Azure Databricks offers an Apache Spark as-a-service workspace environment that is notebook-oriented. It is the most feature-rich hosted service available in Azure for running Spark workloads. Apache Spark is a unified analytics engine for big data and machine learning.
Say you work with Big Data as a data engineer or data scientist, and you need to process data that has one or more of the following characteristics:
- High volume – You must process a massive amount of data and must scale your compute accordingly.
- High velocity – Streaming and real-time processing capabilities are required.
- Variety – Your data is diverse, ranging from structured relational data sets and financial transactions to unstructured data like chat and SMS messages, IoT devices, images, logs, MRIs, and so on.
These characteristics are usually referred to as the “3 Vs of Big Data.”
When it comes to processing Big Data in a unified manner, whether in real time as it arrives or in batches, Apache Spark provides a fast and capable engine that also supports data science processes such as machine learning and advanced analytics.
Architecture of Azure Databricks spark cluster
High-level overview
Within your Azure subscription, the Azure Databricks service launches and manages Apache Spark clusters. Apache Spark clusters are groups of computers that act as a single computer and handle command execution from notebooks. Clusters, which use a master-worker architecture, allow data processing to be parallelized across many computers to improve scale and performance. A Spark Driver (master) and worker nodes comprise them. The driver node dispatches work to the worker nodes, instructing them to retrieve data from a specified data source.
The notebook interface is the driver program in Databricks. This driver program contains the program’s main loop and generates distributed datasets on the cluster before applying operations (transformations and actions) to those datasets. Regardless of deployment location, driver programs access Apache Spark via a SparkSession object.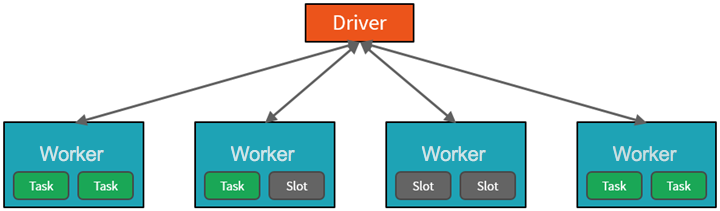
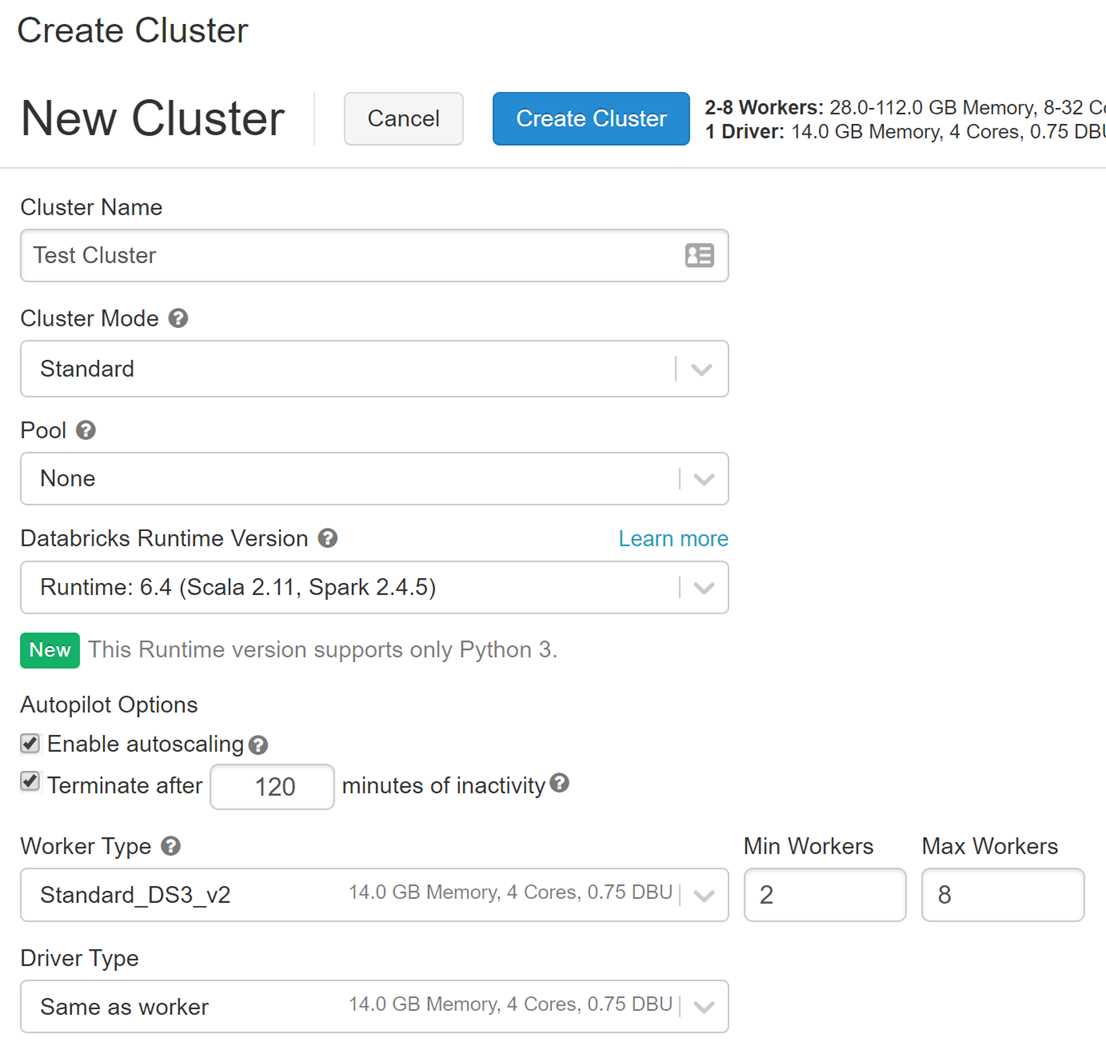
When you create an Azure Databricks service, a “Databricks appliance” is added to your subscription as an Azure resource. You specify the types and sizes of virtual machines (VMs) to use for both the Driver and Worker nodes when you create the cluster, but Azure Databricks manages all other aspects of the cluster.
A Serverless Pool is an additional option. A Serverless Pool is a self-managed cloud resource pool that is pre-configured for interactive Spark workloads. You specify the minimum and maximum number of workers, as well as the type of worker, and Azure Databricks allocates compute and local storage based on your usage.
The “Databricks appliance” is installed as a managed resource group within your Azure subscription. This resource group contains the Driver and Worker virtual machines, as well as other necessary resources such as a virtual network, a security group, and a storage account. For fault tolerance, all metadata for your cluster, such as scheduled jobs, is stored in an Azure Database with geo-replication.
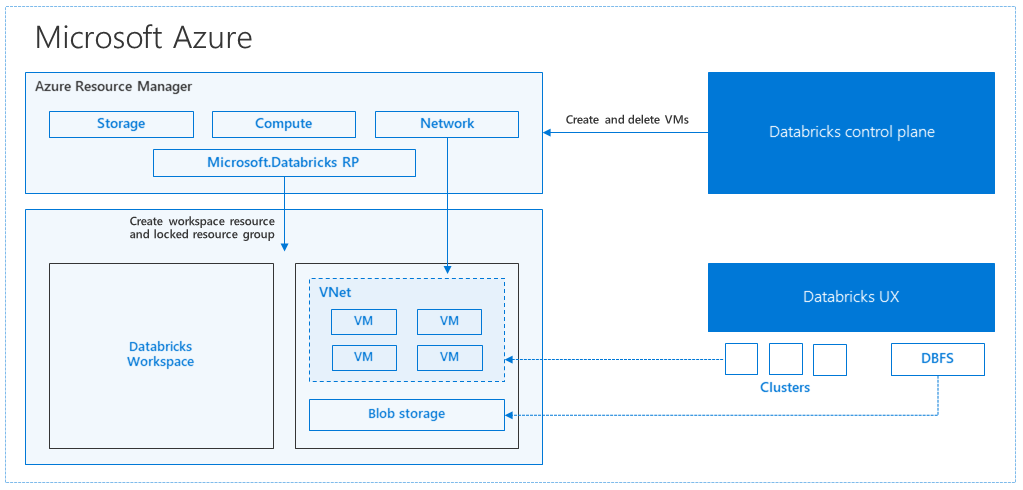
Internally, Azure Kubernetes Service (AKS) is used to run the Azure Databricks control-plane and data-planes via containers running on the most recent generation of Azure hardware (Dv3 VMs), with NvMe SSDs capable of blazing 100us IO latency. These enhance Databricks’ I/O performance. Furthermore, accelerated networking provides the cloud’s fastest virtualized network infrastructure. Azure Databricks makes use of these features to improve Spark performance even further. When the services in this managed resource group are complete, you will be able to manage the Databricks cluster using the Azure Databricks UI and features like auto-scaling and auto-termination.
Architecture of spark job
Spark is a computing environment that is distributed. A Spark Cluster is the distribution unit. A Driver and one or more executors are present in every Cluster. Work submitted to the Cluster is divided into as many separate Jobs as necessary. This is how work is distributed across the nodes of the Cluster. Jobs are further broken down into tasks. A job’s input is divided into one or more partitions. These partitions serve as the work unit for each slot. Partitions may need to be reorganized and shared over the network in between tasks.
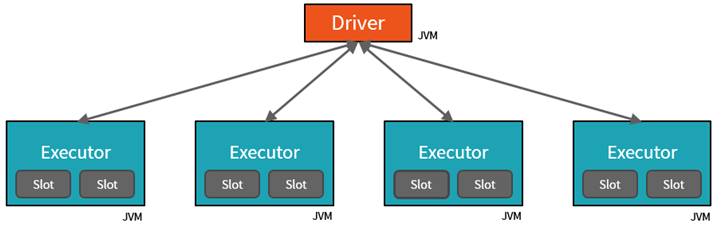
- The JVM in which our application runs is referred to as the Driver.
- Parallelism is the key to Spark’s incredible performance.
- Vertical scaling is limited by a limited amount of RAM, Threads, and CPU speeds.
- When we scale horizontally, we can add new “nodes” to the cluster almost indefinitely.
- At two levels, we parallelize:
- The Executor – a Java virtual machine running on a node, typically one instance per node – is the first level of parallelization.
- The Slot is the second level of parallelization, the number of which is determined by the number of cores and CPUs in each node.
- Each Executor has a number of Slots to which the Driver can assign parallelized Tasks.
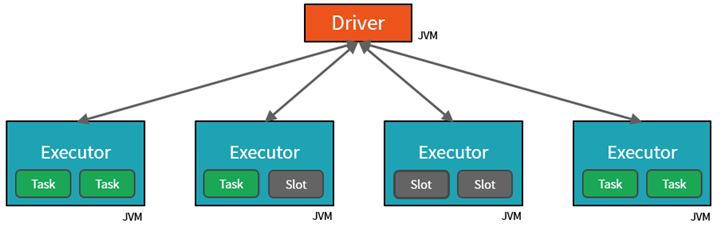
- Although the JVM is naturally multithreaded, a single JVM, such as our Driver, has a finite maximum number of threads.
- The Driver can assign units of work to Slots for parallel execution by creating Tasks.
- Furthermore, the Driver must decide how to partition the data in order for it to be distributed for parallel processing .
- As a result, the Driver assigns a Partition of data to each task, so that each Task knows which piece of data to process.
- Once started, each Task will retrieve the Partition of data assigned to it from the original data source.
Jobs & stages
- A Job is the name given to each parallelized action.
- The Driver receives the results of each Job (parallelized/distributed action).
- Multiple Jobs may be required depending on the work.
- Each job is divided into stages.
- This is analogous to building a house (the job)
- The first step would be to lay the groundwork.
- The walls would be built in the second stage.
- The third stage would be to incorporate the room.
- Trying to do any of these steps out of order will make no sense, if not be impossible.
Cluster management
- Spark Core, on a much lower level, employs a Cluster Manager who is in charge of provisioning nodes in our cluster.
- As part of its overall offering, Databricks includes a robust, high-performance Cluster Manager.
- The Driver is [presumably] running on one node in each of these scenarios, while the Executors are running on N different nodes.
- We don’t need to worry about cluster management for the purposes of this learning path, thanks to Azure Databricks.
- My primary focus as a developer and as a learner is on…
- The number of partitions into which my data is divided.
- The number of parallel execution slots I have.
- How many Jobs am I starting?
- Finally, the jobs are divided into stages.
Apache Spark offers high performance when you need to work with Big Data workloads, because of its distributed computing architecture. When dealing with large amounts of data at a high rate of change. Apache Spark can assist you in processing all of these Big Data scenarios. Apache Spark can be used in a fully managed and fine-tuned environment with Azure Databricks.
Understanding the Spark Cluster and Jobs architecture is a great place to start when learning how to do data engineering and data science in Azure Databricks.


")




")

{kind=link}