
Many companies have spent the previous two decades developing relational database systems-based data warehousing and business intelligence (BI) solutions. Due to the expense and complexity of these forms of data and databases, many BI systems have missed out on opportunities to store unstructured data.
So is there a way that Azure can analyze all of our business data? what is it? Can it enhance the existing business intelligence systems?. Yes, there is a solution for all of these and it is Azure Data Lake Storage.
A data lake is a collection of data stored in its original form, usually as blobs or files. Azure Data Lake Storage is an integrated data lake solution for big data analytics that is comprehensive, scalable, and cost-effective.
Azure Data Lake Storage is a storage platform that combines a file system and a storage system to help you quickly uncover data insights. Data Lake Storage Gen2 extends the capabilities of Azure Blob storage to improve it for analytics workloads. This connection allows analytics performance, as well as Blob storage’s tiering and data lifecycle management capabilities, as well as Azure Storage’s high-availability, security, and durability.
Today, the variety and volume of data created and evaluated is growing. Companies collect data from a variety of sources, including websites, POS systems, and, more recently, social networking sites and Internet of Things (IoT) devices. Each source contributes an important piece of information that must be gathered, examined, and maybe acted upon.
Benefits –
- You can treat the data like it’s in a Hadoop Distributed File System.
- Without moving the data between environments, you can keep it in one location and access it using computing technologies like Azure Databricks, Azure HDInsight, and Azure Synapse Analytics.
Security –
- ACLs (Access Control Lists) and POSIX (Portable Operating System Interface) permissions are supported.
- Permissions for data stored in the data lake can be specified at the directory or file level.
Performance –
- For easy navigation, the data is organized into a hierarchy of folders and subdirectories, similar to a file system.
Data redundancy –
- uses Azure Blob replication techniques to provide data redundancy in a single data center with locally redundant storage (LRS) or to a secondary region with Geo-redundant storage (GRS). This feature ensures that your data is always accessible and secure in the event of a disaster.
Create an Azure Storage Account by using the portal
It’s simple to set up Azure Data Lake Storage Gen2. It requires an Azure Storage account with the Hierarchical namespace enabled and a StorageV2 (General Purpose V2) account. Let’s have a look at how to create a Data Lake Storage account via the Azure interface.
- To access the Azure portal, go to https://portal.azure.com/
- Select Create a resource and type Storage account in the “Search the Marketplace” textbox, then click on Storage account.
- In Storage account screen, click Create.

- Next, make sure your subscription and the relevant resource group are selected in the Create storage account window’s Basics tab, under Project information section. Define a storage account name in the Instance section. Change the region to Central United States. Select Standard from the Performance radio button box, then set the Redundancy to Locally redundant storage (LRS).
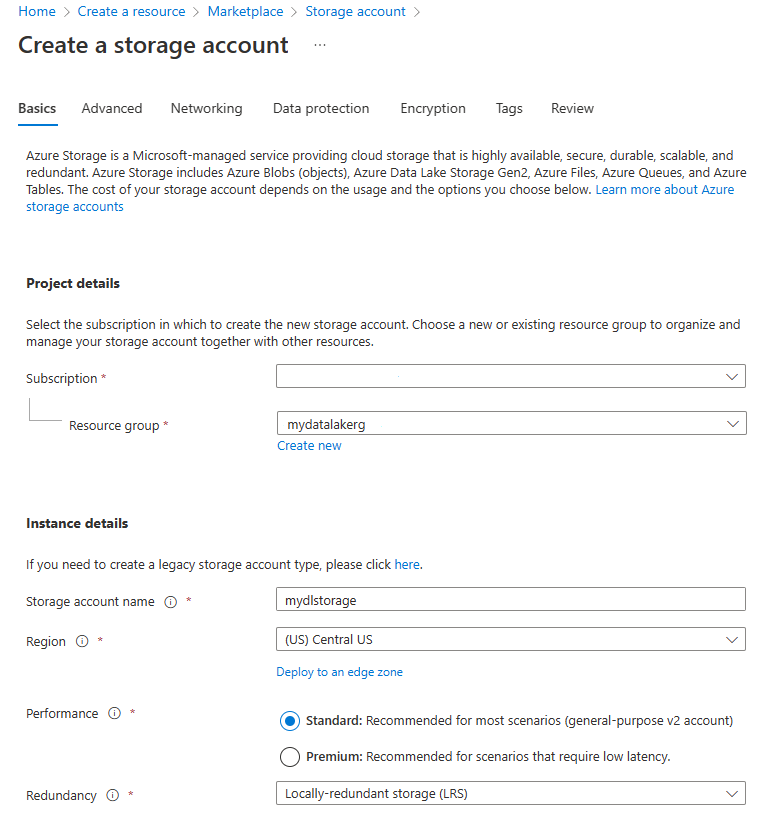
- The Advanced tab should be selected. As shown below, under the section Data Lake Storage Gen2, tick the box next to Enable hierarchical namespace.
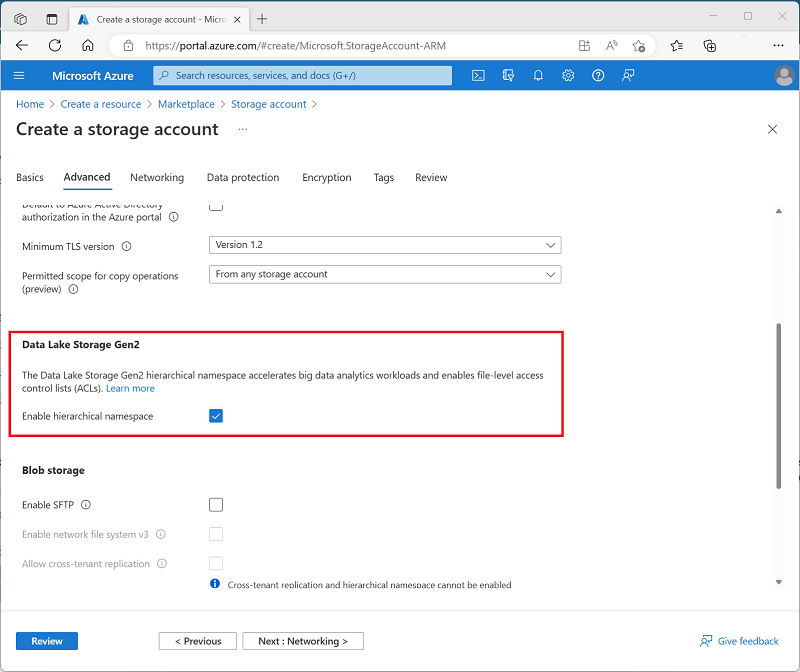
- Click Create after selecting the Review + Create tab.
Compare Azure Data Lake Store to Azure Blob storage
Set the Hierarchical Namespace option to Disabled to set up the storage account as an Azure Blob storage account if you only want to store data without analyzing it. Blob storage can also be used to archive data that is infrequently utilized or to store website assets such as photographs and media.
Set up the storage account as an Azure Data Lake Storage Gen2 account if you’ll be doing analytics on the data, and choose the Hierarchical Namespace option. Applications can access data using either the Blob APIs or the Azure Data Lake Storage Gen2 file system APIs since Azure Data Lake Storage Gen2 is incorporated into the Azure Storage platform.
Stages for processing big data by using Azure Data Lake Store
Azure Data Lake Storage Gen2 is a key component of a variety of big data architectures. These structures may entail the creation of:
- A modern data warehouse.
- Advanced analytics against big data.
- A real-time analytical solution.
There are four stages of large data processing that are common to all architectures:
- Ingestion – identifies the technologies and procedures utilized to obtain the source data.
- Store – indicates the location in which the ingested data should be stored
- Prep and train – outlines the technologies that are used in data science solutions for data preparation, model training, and scoring.
- Model and serve – is concerned with the technologies that will be used to present the data to users. Visualization tools like Power BI, as well as additional data repositories like Azure Synapse Analytics, Azure Cosmos DB, Azure SQL Database, and Azure Analysis Services, are examples.
Uses for Azure Data Lake Storage Gen2
Creating a modern data warehouse

For a modern data warehouse, the architecture places Azure Data Lake Storage at the heart of the solution. To ingest data into the Data Lake from a business application, Integration Services is replaced by Azure Data Factory. This is the place where Azure Databricks gets its prediction model from. PolyBase is used to convert historical data into a big data relational format that is stored in Azure Synapse Analytics, together with the outputs of the Databricks trained model. Azure Analysis Services allows SQL Data Warehouse to cache data so that it can serve a large number of users and be shown in Power BI reports.
Advanced analytics for big data

On an hourly basis, Azure Data Factory uploads terabytes of web logs from a web server to Azure Data Lake. This information is fed into the Azure Databricks predictive model, which is subsequently trained and rated. The results are transmitted globally via Azure Cosmos DB, which will be used by the real-time app (the AdventureWorks website) to make recommendations to clients as they add items to their online shopping carts.
PolyBase is used against the Data Lake to transport descriptive data to the SQL Data Warehouse for reporting purposes, completing this architecture. Azure Analysis Services allows SQL Data Warehouse to cache data so that it can serve a large number of users and be displayed in Power BI reports.
Real-time analytical solutions
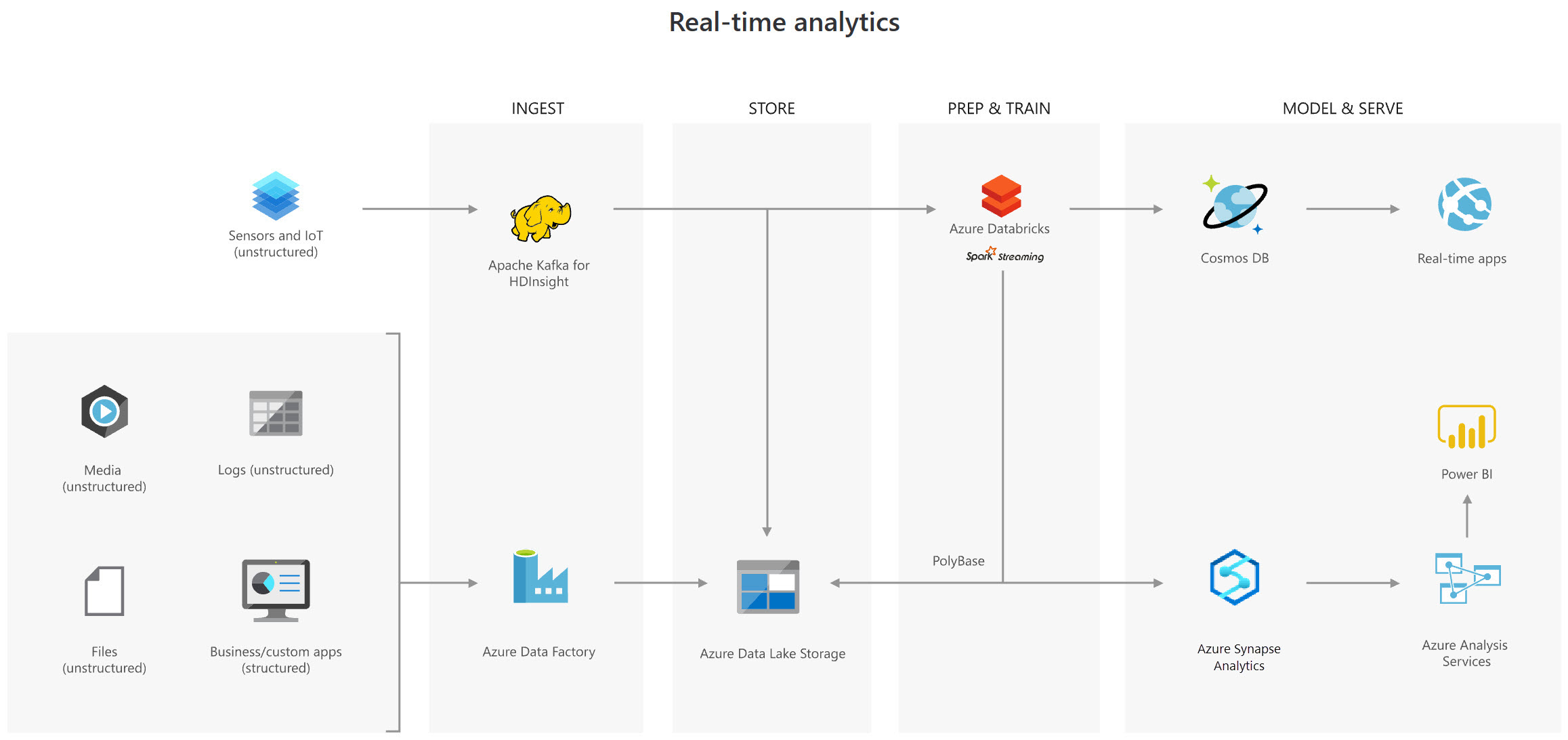
There are two ingestion streams in this design. When the HGV engine is turned off, the summary files are generated and ingested by Azure Data Factory. The real-time ingestion engine for telemetry data is Apache Kafka. Both data streams are saved in Azure Data Lake Store for future use, but they are also provided to other technologies to suit business requirements. The predictive model in Azure Databricks receives both streaming and batch data, and the results are published to Azure Cosmos DB for use by third-party garages. PolyBase moves data from the Data Lake Store to the SQL Data Warehouse, where Azure Analysis Services uses Power BI to build HGV reports.


")




")

{kind=link}